
[Spring] 오라클 데이터베이스 페이징 처리
업데이트:
인덱스를 이용하는 정렬
인덱스에서 가장 중요한 개념 중 하나는 ‘정렬이 되어 있다는 점’이다.
정렬이 이미 되어있는 상태이므로 데이터를 찾아내서 이들을 SORT 하는 과정을 생략할 수 있다.
‘bno의 역순으로 정렬한 결과’를 원한다면 이미 정렬된 인덱스를 이용해서 뒤에서부터 찾아 올라가는 방식을 이용할 수 있다.
이때 ‘뒤에서부터 찾아 올라간다’는 개념이 ‘DESCENDING’이다.

bno의 역순으로 데이터를 가져올 때의 실행 계획을 살펴보면 PK_BOARD라는 인덱스를 이용하는데 DESCENDING을 하고있는 것을 볼 수 있다.
인덱스를 역순으로 찾기 때문에 가장 먼저 찾은 bno 값은 가장 큰 값을 가진 데이터가 된다.
이후에는 테이블에 접근해서 데이터를 가져오게 되는데, 이런 과정이 반복되면 정렬을 하지 않아도 동일하게 정렬된 결과를 볼 수 있게 된다.
만일 사용자가 ‘bno의 순서로 정렬해 달라’고 요구하는 상황이라면 PK_BOARD 인덱스가 앞에서부터 찾아서 내려가는 구조를 이용하는 것이 효율적이다.
SQL Developer를 이용해서 실행해 보면 아래와 같은 실행 계획이 수립되는 것을 볼 수 있다.
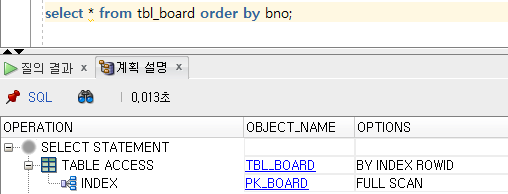
실행 계획상으로 PK_BOARD 인덱스를 먼저 접근하고, TBL_BOARD를 이용하는 것을 볼 수 있다.
SORT가 없기 때문에 0초에 가까운 성능을 보여준다.
실무에서도 데이터의 양이 많고 정렬이 필요한 상황이라면 우선적으로 생각하는 것이 ‘인덱스’를 작성하는 것이다.
데이터의 양이 수천, 수만개 정도의 정렬은 그다지 부하가 걸리지 않지만 그 이상의 데이터를 처리해야 하는 상황이라면 정렬을 안할 수 있는 방법에 대해서 고민해야만 한다.
인덱스와 오라클 힌트(HINT)
웹페이지의 목록은 주로 시간의 역순으로 정렬된 결과를 보여준다.
최신 데이터가 가장 중요하기 때문에 시간의 역순으로 정렬해서 최신 게시물들을 보여주게 된다.
이 경우 개발자의 입장에서는 정렬을 안 하는 방식으로 SELECT문을 실행하고 싶어 한다.
오라클은 SELECT문을 전달할 때 ‘힌트(HINT)’라는 것을 사용할 수 있다.
힌트는 말 그대로 데이터베이스에 ‘지금 내가 전달한 SELECT문을 이렇게 실행해 주면 좋겠습니다’라는 힌트이다.
힌트는 특이하게도 SELECT문을 어떻게 처리하는지에 대한 얘기일 뿐이므로 힌트 구문에서 에러가 나도 전혀 SQL 실행에 지장을 주지 않는다.
따라서 힌트를 이용한 SELECT문을 작성한 후에는 실행 계획을 통해서 개발자가 원하는 대로 SQL이 실행된느지 확인하는 습관을 가져야 한다.
게시물 목록은 반드시 시간의 역순으로 나와야만 하기 때문에 SQL에서는 ‘ORDER BY BNO DESC’와 같은 구문을 추가할 수 있다.
문제는 ‘ORDER BY BNO DESC’와 같은 조건은 데이터베이스 상황에 따라서 테이블의 모든 데이터를 정렬하는 방식으로도 동작할 수 있다는 점이다.
반면에 힌트는 개발자가 데이터베이스에 어떤 방식으로 실행해 줘야 하는지를 명시하기 때문에 조금 강제성이 부여되는 방식이다.
select * from tbl_board order by bno desc;
select /*+INDEX_DESC (tbl_board pk_board) */ *
from tbl_board;
위 두 SQL은 동일한 결과를 생성하는 SQL이다.
두 번째 SELECT문은 ORDER BY 조건이 없어도 동일한 결과가 나온 것에 주목해야 한다.
SELECT문에서 힌트를 부여했는데 힌트의 내용이 ‘tbl_board 테이블에 pk_board 인덱스를 역순으로 이용해 줄 것’이므로 실행 계획에서 이를 활용하고 있는 것을 확인할 수 있다.

오라클 데이터베이스에서 사용할 수 있는 힌트는 여러 종류가 있다.
힌트 사용 문법
SELECT문을 작성할 때 힌트는 잘못 작성되어도 실행할 때는 무시되기만 하고 별도의 에러는 발생하지 않는다.
우선 힌트를 사용할 때에는 다음과 같은 문법을 사용한다.
SELECT
/*+ Hint name (param...) */ column name, ...
FROM
table name
...
힌트 구문은 ‘/+’ 로 시작하고 ‘/’로 마무리 된다.
힌트 자체는 SQL로 처리되지 않기 때문에 위의 그림처럼 뒤에 컬럼명이 나오더라도 별도의 ‘,’로 처리되지 않는다.
FULL 힌트
힌트 중에는 해당 SELECT문을 실행할 때 테이블 전체를 스캔할 것으로 명시하는 FULL 힌트가 있다.
FULL 힌트는 테이블의 모든 데이터를 스캔하기 때문에 데이터가 많을 때는 상당히 느리게 실행된다.
예를 들어, tbl_board 테이블을 FULL 스캔하도록 하고, 이 상태에서 정렬을 하려면 다음과 같이 작성할 수 있다.
select /*+ FULL(tbl_board) */ * from tbl_board order by bno desc;
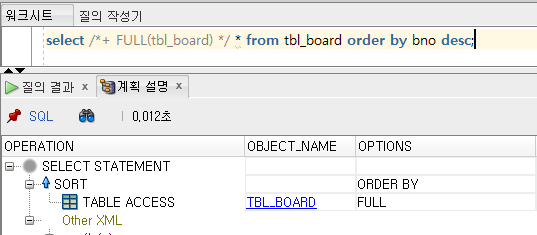
실행 계획을 보면 TBL_BOARD를 FULL로 접근하고, 다시 SORT가 적용된 것을 볼 수 있다.
실행 시간 역시 인덱스를 사용했을 때에 비해서 느리다.
INDEX_ASC, INDEX_DESC 힌트
흔히 목록 페이지에서 가장 많이 사용하는 힌트는 인덱스와 관련된 ‘INDEX_ASC, INDEX_DESC’힌트이다.
ASC/DESC에서 알 수 있듯이 인덱스를 순서대로 이용할것인지 역순으로 이용할 것인지를 지정하는 것이다.
INDEX_ASC/DESC 힌트는 주로 ‘order by’를 위해서 사용한다고 생각하면 된다.
인덱스 자체가 정렬을 해 둔 상태이므로 이를 통해서 SORT 과정을 생략하기 위한 용도이다.
INDEX_ASC/DESC 힌트는 테이블 이름과 인덱스 이름을 같이 파라미터로 사용한다.
select /*+ INDEX_ASC(tbl_board pk_board) */ * from tbl_board
where bno > 0 ;
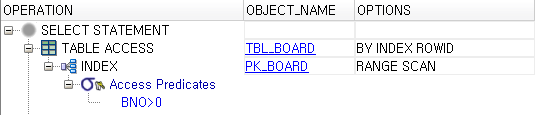
INDEX_ASC/DESC를 이용하는 경우에는 동일한 조건의 order by 구문을 작성하지 않아도 된다.
예를 들어, 위의 SQL에서 아무런 order by 조건이 없어도 bno의 순번을 통해서 접근하기 때문에 ‘order by bno asc’구문은 필요로 하지 않는다.
관련 서적 : 코드로 배우는 스프링 웹 프로젝트
공유하기
Twitter Google+ LinkedIn
댓글남기기