
[Spring] 오라클 데이터베이스 페이징 처리
업데이트:
오라클 데이터베이스 페이징 처리
목록 페이지는 기본적으로 페이징 처리가 필요한데 상식적으로 생각해 봐도 수많은 데이터를 한 페이지에서 보여주면, 처리 성능에 영향을 미친다.
또한, 브라우저에서도 역시 데이터의 양이나 처리 속도에 문제를 일으키게 된다.
일반적으로 페이징 처리는 크게 번호를 이용하거나 ‘계속 보기’ 형태로 구현된다.
번호를 이용한 페이징 처리는 과거 웹 초기부터 이어오던 방식이고, ‘계속 보기’는 Ajax와 앱이 등장한 이후에 ‘무한 스크롤’이나 ‘더 보기’와 같은 형태로 구현된다.
오라클에서 페이징 처리하는 것은 MySQL에 비해서 추가적인 지식이 필요하므로 이에 대한 학습을 선행해야 한다.
order by의 문제
프로그램을 이용해서 정렬을 해 본 적이 있다면 데이터 양이 많을수록 정렬이라는 작업이 얼마나 많은 리소스를 소모하는지 알 수 있다.
데이터베이스는 경우에 따라서 수백만 혹은 천 만개 이상의 데이터를 처리하기 때문에 이 경우 정렬을 하게 되면 엄청나게 많은 시간과 리소스를 소모하게 된다.
데이터베이스를 이용할 때 웹이나 애플리케이션에 가장 신경 쓰는 부분은 1)빠르게 처리 되는 것, 2)필요한 양만큼만 데이터를 가져오는 것이다.
예를 들어, 거의 모든 웹페이지에서 페이징을 하는 이유는 최소한의 필요한 데이터만을 가져와서 빠르게 화면에 보여주기 위함이다.
만일 수백 만개의 데이터를 매번 정렬을 해야 하는 상황이라면 사용자는 정렬된 결과를 볼 때까지 오랜 시간을 기다려야만 하고, 특히 웹에서 동시에 여러 명의 사용자가 정렬이 필요한 데이터를 요청하게 된다면 시스템에는 많은 부하가 걸리게 되고 연결 가능한 커넥션의 개수가 점점 줄어서 서비스가 멈추는 상황을 초래하게 된다.
빠르게 동작하는 SQL을 위해서는 먼저 order by를 이용하는 작업을 가능하면 하지 말아야 한다.
order by는 데이터가 많은 경우에 엄청난 성능의 저하를 가져오기 때문에 1)데이터가 적은 경우와 2)정렬을 빠르게 할 수 있는 방법이 있는 경우가 아니라면 order by는 주의해야만 한다.
실행 계획과 order by
오라클의 페이징 처리를 제대로 이해하기 위해서 반드시 알아두어야 하는 것이 실행 계획(execution plan)이다.
실행 계획은 말 그대로 ‘SQL을 데이터베이스에서 어떻게 처리할 것인가?’에 대한 것이다.
SQL이 데이터베이스에 전달되면 데이터베이스는 여러 단계를 거쳐서 해당 SQL을 어떤 순서와 방식으로 처리할 것인지 계획을 세우게 된다.
데이터베이스에 전달된 SQL문은 아래와 같은 과정을 거쳐서 처리된다.
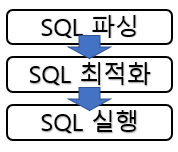
SQL 파싱 단계에서는 SQL 구문에 오류가 있는지 SQL을 실행해야 하는 대상 객체(테이블, 제약 조건, 권한 등)가 존재하는지를 검사합니다.
SQL 최적화 단계에서는 SQL이 실행되는데 필요한 비용(cost)을 계산하게 된다.
이 계산된 값을 기초로 해서 어떤 방식으로 실행하는 것이 가장 좋다는 것을 판단하는 ‘실행 계획(execution plan)’을 세우게 된다.
SQL 실행 단계에서는 세워진 실행 계획을 통해서 메모리상에서 데이터를 읽거나 물리적인 공간에서 데이터를 로딩하는 등의 작업을 하게된다.
개발자들은 도구를 이용하거나 SQL Plus 등을 이용해서 특정한 SQL에 대한 실행 계획을 알아볼 수 있다.
SQL Developer에서는 간단히 버튼을 클릭해서 실행 계획을 확인할 수 있다.
예를 들어, ‘게시물 번호의 역순으로 출력하라’는 처리를 한다면 SQL Developer에서 다음과 같이 처리할 수 있다.
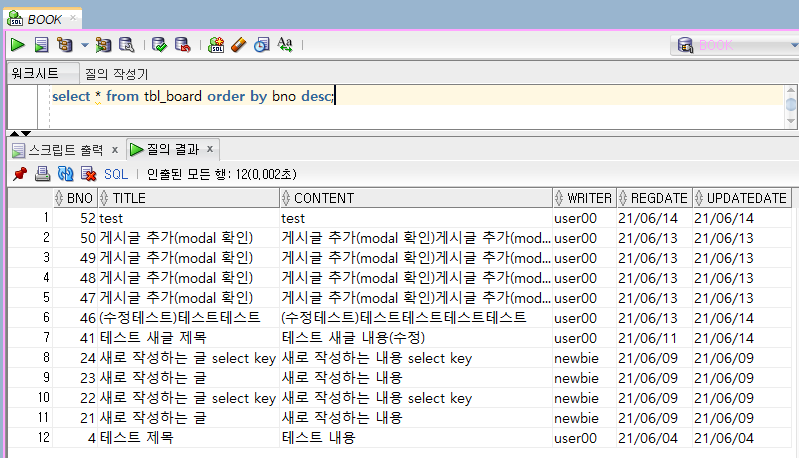
상단의 버튼 중에는 SQL에 대해서 ‘실행 계획’을 쉽게 볼 수 있도록 버튼이 제공된다.
실행 계획을 보면 트리 구조로 방금 전 실행한 SQL이 어떻게 처리된 것인지를 알려준다.
흔히 SQL튜닝이라고 하는 작업은 이를 보고 어떤 방식이 더 효과적인지를 판단해서 수정하게 된다.

가장 간단하게 실행 계획을 보는 방법은 ‘안쪽에서 바깥쪽으로, 위에서 아래로’ 보는 것이다.
위 그림의 내용을 해석하면 ‘TBL_BOARD’테이블을 ‘FULL’로 접근하고 정렬했다는 것을 의미한다.
‘FULL’이라는 의미는 테이블 내의 모든 데이터를 스캔했다는 의미이다.
실행 계획을 세우는 것은 데이터베이스에서 하는 역할이기 때문에 데이터의 양이나 제약 조건 등의 여러 상황에 따라서 데이터베이스는 실행 계획을 다르게 작성한다.
테스트를 위해서 데이터가 좀 많아지도록 아래의 SQL을 여러 번 실행해서 데이터를 수백 만개로 만든 후 커밋을 진행한다.
insert into tbl_board(bno, title, content, writer)
(select seq_board.nextval, title, content, writer from tbl_board);
위의 insert문을 여러 번 실행하게 되면 재귀 복사를 통해서 현재 tbl_board 테이블의 데이터 수만큼 다시 insert가 징행된다.
결과를 보면 insert문을 실행할 때마다 2배씩 데이터가 늘어나게 된다.

commit 후에 ‘select count(*) from tbl_board’를 실행해 보면 데이터의 수가 엄청나게 늘어난 것을 확인할 수 있다.
데이터가 많아지면 정렬에 그마늠 시간을 소모하게 된다.
고의적으로 bno라는 칼럼의 값에다 1을 추가한 값을 역순으로 정렬하는 SQL을 만든다.
select * from tbl_board order by bno + 1 desc;
위의 SQL을 실행한 결과는 테이블 전체를 스캔하는 것을 볼 수 있다.

실행 계획을 살펴보면 TBL_BOARD를 ‘FULL’로 조사했고, 바깥쪽으로 가면서 ‘SORT’가 일어난 것을 볼 수 있다.
이때 가장 많은 시간을 소모하는 작업은 정렬하는 작업이다.
위의 SQL에서 ‘order by bno + 1 desc’라는 조건에서 ‘+1’을 하는 것은 정렬에 아무런 도움을 주지 않으므로 아래와 같이 SQL을 수정해서 실행한다.
select * from tbl_board order by bno desc;
연산이라는 차이가 있기는 하지만 실행에 걸리는 시간은 차이가 많이 나게 된다.

그 이유는 기존의 SQL이 TBL_BOARD 테이블 전체를 스캔했지만, 이번에는 PK_BOARD라는 것을 이용해서 접근하고 기존과 달리 SORT 과정이 없다.
그 이유는 인덱스(index) 때문이다.
order by 보다는 인덱스
데이터가 많은 상태에서 정렬 작업이 문제가 된다는 사실을 알았다면, 이 문제를 어떻게 해결해야 하는지를 살펴봐야 한다.
가장 일반적인 해결책은 ‘인덱스(index)를 이용해서 정렬을 생략하는 방법’이다.
결론부터 말하자면 ‘인덱스’라는 존재가 이미 정렬된 구조이므로 이를 이용해서 별도의 정렬을 하지 않는 방법이다.
select
/*+ INDEX_DESC(tbl_board pk_board) */
*
from
tbl_board
where bno>0;
위의 SQL을 실행한 결과는 테이블 전체를 조사하고 정렬한 것과 결과는 동일하지만 실행 시간은 엄청나게 차이가 나게 된다.
SQL문의 실행 계획은 아래와 같은 모습을 가지게 된다.
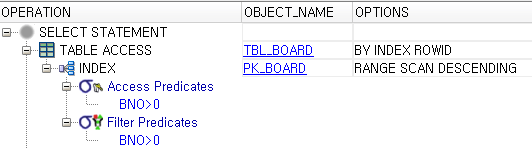
SQL의 실행 계획에서 주의해서 봐야 하는 부분은 1) SORT를 하지 않았다는 점. 2) TBL_BOARD를 바로 접근하는 것이 아니라 PK_BOARD를 이용해서 접근한 점. 3) RANGE SCAN DESCENDING, BY INDEX ROWID로 접근했다는 점이다.
PK_BOARD라는 인덱스
tbl_board 테이블은 생성했을 때의 SQL
create sequence seq_board;
create table tbl_board (
bno number(10,0),
title varchar2(200) not null,
content varchar2(2000) not null,
writer varchar2(50) not null,
regdate date default sysdate,
updatedate date default sysdate
);
alter table tbl_board add constraint pk_board primary key(bno);
테이블을 생성할 때 제약조건으로 PK를 지정하고 PK의 이름이 ‘pk_board’라고 지정했다.
데이터베이스에서 PK는 상당히 중요한 의미를 가지는데, 흔히 말하는 ‘식별자’의 의미와 ‘인덱스’의 의미를 가진다.
데이터베이스에서 인덱스를 이해하는 가장 쉬운 방법은 데이터베이스의 테이블을 하나의 책이라고 생각하고 어떻게 데이터를 찾거나 정렬하는지를 생각하는 것이다.
색인은 사람들이 쉽게 찾아볼 수 있게 알파벳 순서나 한글 순서로 정렬한다.
이를 통해서 원하는 내용을 위에서부터 혹은 반대로 찾아나가는데 이를 ‘스캔’이라고 한다.
데이터베이스에 테이블을 만들 때 PK를 부여하면 지금까지 얘기한 ‘인덱스’라는 것이 만들어진다.
데이터베이스를 만들 때 PK를 지정하는 이유는 ‘식별’이라는 의미가 있지만, 구조상으로는 ‘인덱스’라는 존재(객체)가 만들어지는 것을 의미한다.
tbl_board 테이블의 bno라는 칼럼을 기준으로 인덱스를 생성하게 된다.
인덱스에는 순서가 있다.
인덱스는 순서대로 정렬되지만, 테이블은 순서가 섞여 있는 경우가 대부분이다.
인덱스와 실제 테이블을 연결하는 고리는 ROWID라는 존대이다.
ROWID는 데이터베이스 내의 주소에 해당하는데 모든 데이터는 자신만의 주소를 가지고 있다.
SQL을 통해서 bno 값이 100번인 데이터를 찾고자 할 때 SQL은 ‘where bno = 100’과 같은 조건을 주게 된다.
이를 처리하는 데이터베이스 입장에서는 tbl_board라는 책에서 bno 값이 100인 데이터를 찾아야 하는데 만일 책이 얇아서 내용이 많이 않다면 빠르게 전체를 살펴보는 것이 더 빠르다.(이를 데이터베이스 쪽에서는 FULL SCAN이라고 한다.) 하지만 내용이 많고, 색인이 존재한다면 당연히 색인을 찾고 색인에서 주소를 찾아서 접근하는 방식을 이용할 거다.
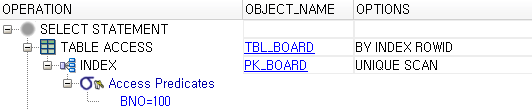
실행 계획을 보면 PK_BOARD는 인덱스이므로 먼저 인덱스를 이용해서 100번 데이터가 어디에 있는지 ROWID를 찾아내고, 바깥쪽을 보면 ‘BY INDEX ROWID’라고 되어있는 말 그대로 ROWID를 통해서 테이블에 접근하게 된다.
관련 서적 : 코드로 배우는 스프링 웹 프로젝트
공유하기
Twitter Google+ LinkedIn
댓글남기기